Next: ZCA Up: Eigenvalue Analysis Previous: Eigenvalue Analysis
Principal Component Analysis, or the discrete Karhunen-Loeve transform KLT, is a technique that has two significant applications in data analysis:
Similarly, there are two formulations of the PCA definition:
A practical example of dimensionality reduction is the equation of a hyperplane in  dimensions: there exists a basis of the space that transforms the equation of the plane, reducing it to
dimensions: there exists a basis of the space that transforms the equation of the plane, reducing it to  dimensions without losing information, thereby saving one dimension in the problem.
dimensions without losing information, thereby saving one dimension in the problem.
Let us consider
 random vectors representing the outcomes of some experiment, realizations of a zero-mean random variable, which can be stored in the rows2.1 of the matrix
random vectors representing the outcomes of some experiment, realizations of a zero-mean random variable, which can be stored in the rows2.1 of the matrix  of dimensions
of dimensions  , which therefore stores
, which therefore stores  random vectors of dimensionality and with
random vectors of dimensionality and with  .
Each line corresponds to a different result
.
Each line corresponds to a different result  , and the distribution of these experiments must have a mean, at least the empirical one, equal to zero.
, and the distribution of these experiments must have a mean, at least the empirical one, equal to zero.
Assuming that the points have zero mean (which can always be achieved by simply subtracting the centroid), their covariance of occurrences is given by
 |
(2.66) |
are correlated, the covariance matrix
 is not a diagonal matrix.
is not a diagonal matrix.
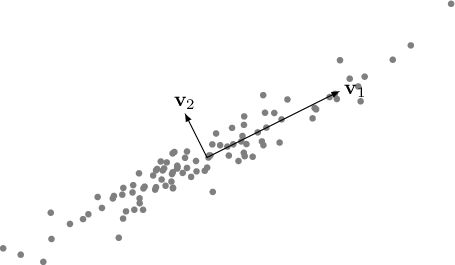
The objective of PCA is to find an optimal transformation  that transforms the correlated data into uncorrelated data
that transforms the correlated data into uncorrelated data
 |
(2.67) |
If there exists an orthonormal basis such that the covariance matrix of
 expressed in this basis is diagonal, then the axes of this new basis are referred to as the principal components of
(or of the distribution of
expressed in this basis is diagonal, then the axes of this new basis are referred to as the principal components of
(or of the distribution of  ). When a covariance matrix is obtained where all elements are
). When a covariance matrix is obtained where all elements are  except for those on the diagonal, it indicates that under this new basis of the space, the events are uncorrelated with each other.
except for those on the diagonal, it indicates that under this new basis of the space, the events are uncorrelated with each other.
This transformation can be found by solving an eigenvalue problem: it can indeed be demonstrated that the elements of the diagonal correlation matrix must be the eigenvalues of  , and for this reason, the variances of the projection of the vector onto the principal components are the eigenvalues themselves:
, and for this reason, the variances of the projection of the vector onto the principal components are the eigenvalues themselves:
is the matrix of eigenvectors (orthogonal matrix
 ) and
) and
 is the diagonal matrix of eigenvalues
is the diagonal matrix of eigenvalues
 .
.
To achieve this result, there are two approaches. Since
is a symmetric, real, positive definite matrix, it can be decomposed into
being an orthonormal matrix, the right eigenvalues of
, and
is the diagonal matrix containing the eigenvalues. Since the matrix
is positive definite, all eigenvalues will be positive or zero. By multiplying the equation (2.69) on the right by , it is shown that it is indeed the solution to the problem (2.68).
This technique, however, requires the explicit computation of
. Given a rectangular matrix , the SVD technique allows us to precisely find the eigenvalues and eigenvectors of the matrix
 , that is, of
, and therefore it is the most efficient and numerically stable method to achieve this result.
, that is, of
, and therefore it is the most efficient and numerically stable method to achieve this result.
Through the SVD, it is possible to decompose the event matrix such that

 are the left singular vectors,
are the left singular vectors,  are the eigenvalues of
, and are the right singular vectors.
are the eigenvalues of
, and are the right singular vectors.
It is noteworthy that using the SVD, it is not necessary to explicitly compute the covariance matrix
. However, this matrix can be derived later through the equation
 |
(2.70) |
By comparing this relation with that of equation (2.69), it can also be concluded that
 .
.
It is important to remember the properties of eigenvalues:
 and
are the same.
, which is the covariance matrix;
and
are the same.
, which is the covariance matrix;
 approximation closest to . This fact, combined with the inherent characteristic of SVD to return the singular values of ordered from largest to smallest, allows for the approximation of a matrix to one of lower rank.
approximation closest to . This fact, combined with the inherent characteristic of SVD to return the singular values of ordered from largest to smallest, allows for the approximation of a matrix to one of lower rank.
By selecting the number of eigenvectors with sufficiently large eigenvalues, it is possible to create an orthonormal basis  of the space
of the space
 such that
such that
 obtained as a projection
obtained as a projection

instead of and vice versa.