Next: SURF Up: Characteristic Points Previous: Förstner-Harris
Harris is a feature point detector that is not invariant to scale variations. To overcome this series of limitations, Lindeberg (Lin94,Lin14) introduces the concept of automatic scale selection, allowing for the identification of characteristic points at a specific level of resolution. The pyramid representation of the scene, a computationally efficient algorithm widely used previously, effectively becomes a special case of this scale-space representation.
Let  be the two-dimensional Gaussian with variance
be the two-dimensional Gaussian with variance  , described by the equation
, described by the equation
 |
(5.6) |
The convolution  between the image
between the image  and the Gaussian
and the Gaussian
 |
(5.7) |
 of the Gaussian kernel is referred to as the scale parameter.
The representation of the image at the degenerate scale
of the Gaussian kernel is referred to as the scale parameter.
The representation of the image at the degenerate scale  is the original image itself.
is the original image itself.
It is noteworthy that applying a Gaussian filter to an image does not create new structures: all the information generated by the filter was already contained in the original image.





 |
The scale factor  is a continuous number; however, for computational reasons, discrete steps of this value are used, typically exponential sequences, such as
is a continuous number; however, for computational reasons, discrete steps of this value are used, typically exponential sequences, such as  or
or
 .
.
Applying a scale-space image operator, using the commutative property between convolution and differentiation, is equivalent to convolving the original image with the derivative of the Gaussian:
 |
(5.8) |
 multi-index notation for the derivative. Similarly, it is possible to extend the definition of all edge or feature point filters to any scale factor. Through the work of Lindeberg, it has been possible to extend the concept of Harris Corners to scale-invariant cases (Harris-Laplace and Hessian-Laplace methods (MS02)).
multi-index notation for the derivative. Similarly, it is possible to extend the definition of all edge or feature point filters to any scale factor. Through the work of Lindeberg, it has been possible to extend the concept of Harris Corners to scale-invariant cases (Harris-Laplace and Hessian-Laplace methods (MS02)).
Some interesting operators for identifying characteristic points include the gradient magnitude  , the Laplacian
, the Laplacian  , and the determinant of the Hessian
, and the determinant of the Hessian
 . All of these operators are invariant to rotations, meaning that the location of the minimum/maximum point exists independently of the rotation of the image.
. All of these operators are invariant to rotations, meaning that the location of the minimum/maximum point exists independently of the rotation of the image.
Among these operators, a widely used one for identifying characteristic points is the normalized Laplacian of Gaussian (LoG) operator:
 |
(5.9) |
Through the LoG operator, it is possible to identify characteristic points such as local maxima or minima in spatial coordinates and scale.
For example, a circle with radius  has the maximum response to the Laplacian at the scale factor
has the maximum response to the Laplacian at the scale factor
 .
.
Lowe (Low04), in the Scale-invariant feature transform (SIFT) algorithm, enhances performance by approximating the Laplacian of the Gaussian (LoG) with a Difference of Gaussians (DoG):
 |
(5.10) |
This procedure is more efficient because the Gaussian image at scale  can be computed from the Gaussian image
can be computed from the Gaussian image  by applying a smaller filter
by applying a smaller filter  , and therefore is overall much faster compared to performing the convolution with the original image.
, and therefore is overall much faster compared to performing the convolution with the original image.
If in LoG the characteristic points were the local minima/maxima, both in space and scale, of the Laplacian image, in this case, the characteristic points are the minimum and maximum points in the difference image between the scale images
 through which the image is processed (figure 5.4).
through which the image is processed (figure 5.4).
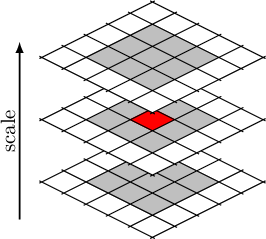 |
With the introduction of step  , the domain of the variable is effectively divided into discrete logarithmic steps, grouped into octaves, and each octave is subdivided into
, the domain of the variable is effectively divided into discrete logarithmic steps, grouped into octaves, and each octave is subdivided into  sub-levels.
In this way, takes on the discrete values
sub-levels.
In this way, takes on the discrete values
 |
(5.11) |
 as the base scaling factor.
as the base scaling factor.
The characteristic points, identified as maxima/minima in both discrete scale and space, are interpolated using a regression on a three-dimensional quadratic to determine the characteristic point with subpixel and subscale precision.
Between one octave and the next, the image is downsampled by a factor of 2: in addition to the multi-scale analysis within each octave, the image is processed again in the subsequent octave by halving both the horizontal and vertical dimensions, and this procedure is repeated multiple times.
The second phase of a feature detection and matching algorithm involves extracting a descriptor to perform comparisons, with the descriptor centered on the identified feature point. In fact, to be scale-invariant, the descriptor must be extracted at the same scale factor associated with the feature point.
To be invariant to rotation, the descriptor must be extracted from an image that has undergone some form of normalization with respect to the dominant direction identified in the vicinity of the evaluated point.
From this rotated image at the scale of the characteristic point, it is possible to extract a descriptor that emphasizes the edges in the surrounding area, ultimately making it invariant to brightness.
Among the numerous variants, PCA-SIFT should be noted, which utilizes PCA to reduce the dimensionality of the problem to a descriptor consisting of only 36 elements. PCA is employed in a prior training phase.
Paolo medici



