Next: Generalizing the Training Up: Deep Learning Previous: Convolutional Neural Networks
Convolutional Neural Networks (CNNs) represented a breakthrough in the processing of static images, due to their ability to capture hierarchies of local features through convolutional filters and pooling. However, traditional CNNs are not well suited for handling sequential data such as text, time signals, or video, where order and temporal dependencies among elements are crucial. To address these challenges, Recurrent Neural Networks (RNNs) were introduced, in which neurons are equipped with recurrent connections that enable the maintenance of a memory of past states. RNNs have been applied to tasks such as speech recognition, machine translation, time-series analysis, and automatic image captioning. Nevertheless, standard RNNs struggle to learn long-term dependencies due to the vanishing and exploding gradient problems. To mitigate these limitations, more sophisticated architectures such as Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) were developed, capable of regulating which information to retain or discard through gating mechanisms.
Despite these advances, the first generation of deep sequential networks relied on an encoder?decoder paradigm, in which the information from the input sequence was compressed into a lower-dimensional tensor, expected to preserve as much relevant information as possible for the downstream task. This approach, however, suffers from an intrinsic limitation: important input elements may be overlooked or attenuated during compression.
A fundamental shift came with the introduction of the attention mechanism. The underlying idea of attention is simple yet powerful: instead of compressing all information into a single vector, the model can dynamically ?focus? on the most relevant parts of the input sequence. Attention weights are computed according to the relevance of each element with respect to the others, overcoming the limitations of compressed recurrent representations.
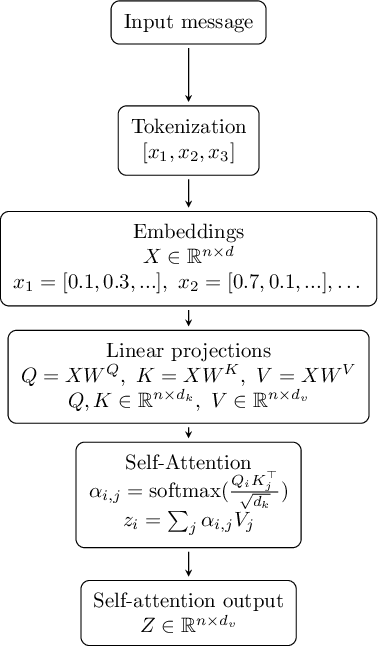
Let
 be the input sequence matrix, where
be the input sequence matrix, where  is the number of tokens (the individual units into which the algorithm divides the input sequence, varying from sequence to sequence) and
is the number of tokens (the individual units into which the algorithm divides the input sequence, varying from sequence to sequence) and  is the embedding dimension (a numerical vector representing each token, fixed for the model and encoding semantic and syntactic information).
is the embedding dimension (a numerical vector representing each token, fixed for the model and encoding semantic and syntactic information).
The query ( ), key (
), key ( ), and value (
), and value ( ) matrices are obtained through linear projections:
) matrices are obtained through linear projections:
 and
and
 are weight matrices learned during training;
are weight matrices learned during training;
 and
and
 .
.
The self-attention mechanism can then be expressed in scalar form (for a single token) as:
 are, respectively, the query of token
are, respectively, the query of token  and the key of token
and the key of token  ;
;
 is the value of token ;
is the value of token ;
 is the scalar weight indicating the degree to which token attends to token ;
is the scalar weight indicating the degree to which token attends to token ;
 is the new representation of token resulting from the weighted combination of values.
between 0 and 1, is defined as:
is the new representation of token resulting from the weighted combination of values.
between 0 and 1, is defined as:
 is the input vector (in our case,
is the input vector (in our case,
 for row ).
for row ).
Intuitively, attention can be seen as a dynamic generalization of weighting methods such as Bag of Words or TF-IDF. Unlike TF-IDF, which assigns static weights to terms, attention assigns context- and task-dependent weights, enabling the model to focus selectively on the most relevant parts. Semantically, the resulting matrix  has the same length as the input ( tokens in, tokens out), but each token is enriched with contextual information from the entire sequence.
has the same length as the input ( tokens in, tokens out), but each token is enriched with contextual information from the entire sequence.
The attention mechanism directly led to the development of Transformers (VSP$^+$17), which are now the de facto standard for sequence modeling in natural language processing, computer vision, and multimodal learning. In Transformers, the central operator is self-attention, which models relationships among all sequence elements in parallel and directly. Compared to RNNs, Transformers provide substantial advantages in terms of parallelization, numerical stability, and the ability to capture long-range dependencies.
In computer vision, the application of Transformers gave rise to the Vision Transformers (ViT) (DBK$^+$20), where an image is partitioned into small patches treated as a sequence, analogous to words in a text. These models have demonstrated performance that is competitive with or superior to CNNs on various classification, recognition, and segmentation tasks, particularly in the presence of large-scale datasets.
In practical applications, a single self-attention module is insufficient to extract adequate information from the input tokens. The multi-head self-attention mechanism extends the idea of self-attention by allowing the model to examine the sequence from multiple perspectives simultaneously. Specifically:
 distinct heads are employed. For each head
distinct heads are employed. For each head
 , separate projection matrices are defined:
, separate projection matrices are defined:
 .
.
 denotes the scaled dot-product attention operator:
-dimensional space (the model dimension) through an output matrix
denotes the scaled dot-product attention operator:
-dimensional space (the model dimension) through an output matrix
 :
:
 and
and
 , so that concatenation followed by projection yields a dimension consistent with the input to the next layer.
, so that concatenation followed by projection yields a dimension consistent with the input to the next layer.
| Model | Layers |  |
 |
 |
|---|---|---|---|---|
| Transformer (base) (VSP$^+$17) | 6 encoder + 6 decoder | 512 | 8 | 64 |
| BERT-Base | 12 encoder | 768 | 12 | 64 |
| BERT-Large | 24 encoder | 1024 | 16 | 64 |
| GPT-3 (175B) | many decoders | 12288 | 96 | 128 |
Today, RNNs and Transformers are best seen as complementary tools: the former remain useful in scenarios with relatively short sequences or limited resources, while the latter constitute the foundation of modern state-of-the-art deep learning architectures. The evolution from recurrent to attention-based mechanisms has marked a paradigm shift: from the notion of compressed memory to dynamic, context-dependent representations, where the model autonomously decides ?what to attend to? for each element of the sequence.
Paolo medici





![\begin{displaymath}
Z_{\text{concat}} = \big[Z^{(1)} \, ; \, Z^{(2)} \, ; \, \dots \, ; \, Z^{(h)}\big] \in \mathbb{R}^{n \times (h \cdot d_v)}
\end{displaymath}](img1369.svg)
