Next: Recurrent Neural Networks and Up: Deep Learning Previous: Deep Neural Networks
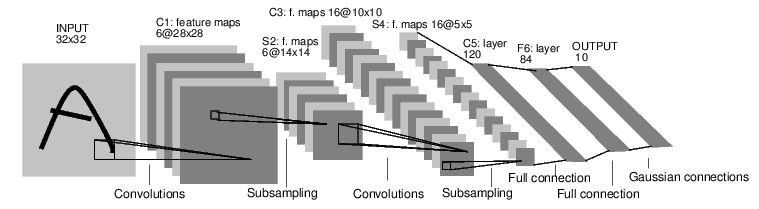
Convolutional Neural Networks (CNNs) represent a natural evolution of deep neural networks for the processing of spatially structured data, such as images. In contrast to classical MultiLayer Perceptrons (MLPs), CNNs exploit local pixel correlations and spatial redundancy through convolutional layers in which weights are shared. This architectural principle enables the automatic learning of hierarchical and translation-invariant features, significantly reducing the number of parameters to be optimized and thereby improving training efficiency. The following paragraphs describe the main components of a CNN, including convolutional layers, activation functions, pooling, and the typical architectures used in deep training.
CNNs are multi-layer neural networks similar to MultiLayer Perceptrons, but with a distinctive structure: at least one of the layers consists of sets of neurons with shared weights, referred to as convolutional layers.
In a convolutional layer, the activation of a neuron depends on the dot product between a kernel (or filter) and a local region of the input:
 |
(4.88) |
 denotes the filter weights,
denotes the filter weights,
 the local portion of the image centered at
the local portion of the image centered at  , and
, and  a possible bias term.
a possible bias term.
Convolution can be applied with a stride greater than 1, thereby producing a downsampled activation map relative to the input. Since filters progressively reduce the spatial resolution of activation maps, it is common to introduce padding in order to preserve the output dimensions.
Activation maps are then transformed by a nonlinear activation function, typically a ReLU. Subsequently, a pooling layer is often employed to reduce dimensionality and introduce local invariance: max pooling is the most widely used variant, whereas average pooling and L2-norm pooling were more common in earlier architectures.
CNNs are specifically designed to leverage multi-channel two-dimensional inputs.
Typically, a CNN accepts as input a third- or fourth-order tensor; for example, an image of size  with three channels (R,G,B) corresponds to a third-order tensor.
Each convolutional layer may contain
with three channels (R,G,B) corresponds to a third-order tensor.
Each convolutional layer may contain  distinct kernels, producing output activation maps of size
distinct kernels, producing output activation maps of size
 .
.
The architecture of a deep neural network (DNN) may include:
At the final stage (the loss layer), a traditional classification method (MLP, AdaBoost, or SVM) is applied to the reduced representation of the input, preserving most of the useful information.
The training of DNNs is typically performed through variants of stochastic gradient descent (see section 3.3.3), iteratively optimizing the weights of the filters and fully connected layers on the basis of the classification error.
Paolo medici