Next: Generalizzare l'addestramento Up: Apprendimento Profondo Previous: Reti Neurali Convolutive
Le Convolutional Neural Networks (CNN) hanno rappresentato una svolta per l'elaborazione delle immagini statiche, grazie alla capacità di catturare gerarchie di caratteristiche locali attraverso filtri convolutivi e pooling. Tuttavia, le CNN tradizionali non sono adatte a gestire dati sequenziali come testo, segnali temporali o video, in cui l'ordine e la relazione temporale tra gli elementi è cruciale. Per affrontare questi problemi, sono state introdotte le Reti Neurali Ricorrenti (RNN), in cui i neuroni presentano connessioni ricorrenti che consentono di mantenere una memoria dello stato passato. Le RNN hanno trovato applicazione in compiti come il riconoscimento del parlato, la traduzione automatica, l'analisi di serie temporali e la descrizione automatica di immagini (image captioning). Tuttavia, le RNN tradizionali soffrono di difficoltà nell'apprendere dipendenze a lungo termine, a causa del problema del gradiente evanescente o esplodente. Per mitigare questi limiti sono state sviluppate architetture più sofisticate come le Long Short-Term Memory (LSTM) e le Gated Recurrent Unit (GRU), capaci di controllare quali informazioni mantenere o dimenticare attraverso meccanismi di gating.
Nonostante ciò, la prima generazione di reti neurali profonde sequenziali si basava su un paradigma encoder-decoder, in cui l'informazione della sequenza in ingresso veniva compressa in un tensore di dimensioni ridotte, che doveva preservare il maggior numero possibile di informazioni utili per il compito. Questo approccio ha tuttavia un limite intrinseco: elementi rilevanti dell'input possono essere trascurati o attenuati durante la compressione.
Un cambiamento fondamentale è arrivato con il “meccanismo di attenzione” (attention mechanism). L'idea alla base dell'attenzione è semplice ma potente: invece di comprimere tutte le informazioni in un unico vettore, il modello può “concentrarsi” dinamicamente sulle parti più rilevanti della sequenza di ingresso. I pesi di attenzione vengono calcolati in base alla rilevanza di ciascun elemento rispetto agli altri, permettendo di superare le limitazioni delle rappresentazioni compresse negli stati ricorrenti.
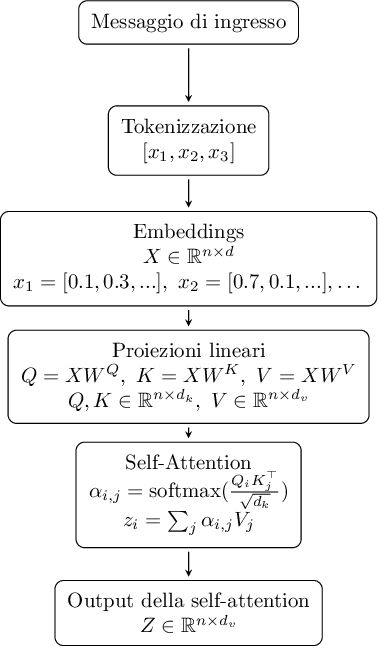
Sia
 la matrice di input della sequenza, dove
la matrice di input della sequenza, dove  è il numero di token (le singole unità in cui l'algoritmo divide la sequenza di ingresso, variabile da sequenza a sequenza) e
è il numero di token (le singole unità in cui l'algoritmo divide la sequenza di ingresso, variabile da sequenza a sequenza) e  è la dimensione degli embedding (un vettore numerico che rappresenta ciascun token, fisso per il modello e capace di codificare informazioni semantiche e sintattiche).
è la dimensione degli embedding (un vettore numerico che rappresenta ciascun token, fisso per il modello e capace di codificare informazioni semantiche e sintattiche).
Le matrici, chiamate di query ( ), key (
), key ( ) e value (
) e value ( ), si ottengono tramite proiezioni lineari:
), si ottengono tramite proiezioni lineari:
 e
e
 sono matrici di pesi apprese durante l'addestramento;
sono matrici di pesi apprese durante l'addestramento;
 e
e
 .
.
Il meccanismo di self-attention può allora essere espresso in forma scalare (per singolo token) come:
 sono rispettivamente la query del token
sono rispettivamente la query del token  e la key del token
e la key del token  ;
;
 è il value del token ;
è il value del token ;
 è lo scalare che indica quanto il token presta attenzione al token ;
è lo scalare che indica quanto il token presta attenzione al token ;
 è la nuova rappresentazione del token risultante dalla combinazione pesata dei value.
tra 0 e 1, è definita come:
è la nuova rappresentazione del token risultante dalla combinazione pesata dei value.
tra 0 e 1, è definita come:
 è il vettore di input (nel nostro caso
è il vettore di input (nel nostro caso
 per la riga ).
per la riga ).
In termini intuitivi, l'attenzione può essere vista come una generalizzazione dinamica dei metodi di ponderazione come Bag of Words o TF-IDF. Tuttavia, mentre TF-IDF assegna pesi statici ai termini, l'attenzione attribuisce pesi contestuali e dipendenti dal compito, consentendo al modello di focalizzarsi selettivamente sulle parti più rilevanti. Semanticamente, la matrice  risultante ha la stessa lunghezza dell'ingresso ( token in, token out), ma ogni token è arricchito con informazioni provenienti dal contesto globale della sequenza.
risultante ha la stessa lunghezza dell'ingresso ( token in, token out), ma ogni token è arricchito con informazioni provenienti dal contesto globale della sequenza.
Il meccanismo di attenzione ha portato direttamente allo sviluppo dei Transformers (VSP$^+$17), oggi lo standard de facto per la modellazione di sequenze in linguaggio naturale, visione artificiale e apprendimento multimodale. Nei Transformers, l'operatore centrale è il self-attention, che consente di modellare in modo parallelo e diretto le relazioni tra tutti gli elementi della sequenza. Rispetto alle RNN, i Transformers offrono vantaggi significativi in termini di parallelizzazione, stabilità numerica e capacità di apprendere dipendenze a lungo raggio.
Nel campo della visione artificiale, l'applicazione dei Transformers ha portato allo sviluppo dei Vision Transformers (ViT) (DBK$^+$20), in cui un'immagine viene suddivisa in piccole regioni (patch) trattate come una sequenza, analogamente alle parole in un testo. Questi modelli hanno dimostrato prestazioni competitive o superiori rispetto alle CNN su vari compiti di classificazione, riconoscimento e segmentazione, soprattutto in presenza di grandi quantità di dati.
In applicazioni pratiche un solo modulo di self-attention non risulta sufficiente per estrarre abbastanza informazione dai token di ingresso. Il meccanismo di multi-head self-attention estende l'idea di self-attention permettendo al modello di guardare la sequenza sotto diverse prospettive contemporaneamente. In pratica:
 teste (heads) diverse. Per ciascuna head
teste (heads) diverse. Per ciascuna head
 , si hanno matrici di proiezione separate:
, si hanno matrici di proiezione separate:
 .
.
 è l'operatore scaled dot-product attention:
(la dimensione del modello), tramite una matrice di uscita
è l'operatore scaled dot-product attention:
(la dimensione del modello), tramite una matrice di uscita
 :
:
 , e
, e
 , cosı che la concatenazione seguita dalla proiezione restituisca una dimensione coerente con l'input del layer successivo.
, cosı che la concatenazione seguita dalla proiezione restituisca una dimensione coerente con l'input del layer successivo.
| Modello | Layers |  |
 |
 |
|---|---|---|---|---|
| Transformer (base) (VSP$^+$17) | 6 encoder + 6 decoder | 512 | 8 | 64 |
| BERT-Base | 12 encoder | 768 | 12 | 64 |
| BERT-Large | 24 encoder | 1024 | 16 | 64 |
| GPT-3 (175B) | molti decoder | 12288 | 96 | 128 |
Oggi, RNN e Transformers rappresentano strumenti complementari: le prime restano utili in scenari con sequenze relativamente brevi o risorse limitate, mentre i secondi costituiscono la base delle architetture più avanzate del deep learning moderno. L'evoluzione dai meccanismi ricorrenti a quelli basati su attenzione ha segnato un cambio di paradigma: dall'idea di memoria compressa ad una rappresentazione dinamica e contestuale, dove il modello decide autonomamente “cosa guardare” per ogni elemento della sequenza.
Paolo medici





![\begin{displaymath}
Z_{\text{concat}} = \big[Z^{(1)} \, ; \, Z^{(2)} \, ; \, ...
...\, ; \, Z^{(h)}\big] \in \mathbb{R}^{n \times (h \cdot d_v)}
\end{displaymath}](img1401.svg)
