Next: Reti Ricorrenti e Transformers Up: Apprendimento Profondo Previous: Reti Neurali Profonde
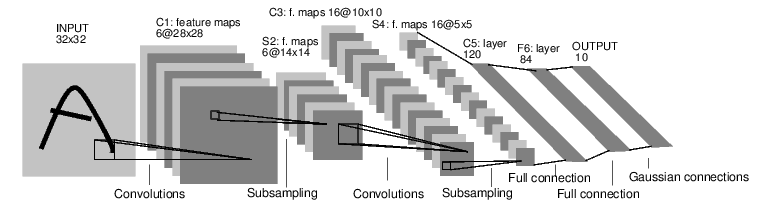
Le Convolutional Neural Networks (CNN) rappresentano una naturale evoluzione delle reti neurali profonde per il trattamento di dati strutturati spazialmente, come le immagini. A differenza dei classici MultiLayer Perceptron (MLP), le CNN sfruttano la correlazione locale dei pixel e la ridondanza spaziale attraverso strati convolutivi in cui i pesi sono condivisi. Questa architettura permette di apprendere automaticamente caratteristiche gerarchiche e invarianti rispetto alla traslazione, riducendo significativamente il numero di parametri da ottimizzare e migliorando l'efficienza dell'apprendimento. Nei paragrafi seguenti verranno descritti i principali componenti di una CNN, tra cui i layer convolutivi, le funzioni di attivazione, il pooling e le architetture tipiche di addestramento profondo.
Le CNN sono reti neurali multi-livello simili ai MultiLayer Perceptron, ma con una struttura peculiare: almeno uno degli strati è costituito da insiemi di neuroni che condividono i pesi, detti strati convolutivi (convolutional layer).
In uno strato convolutivo, l'attivazione di un neurone dipende dal prodotto scalare tra un kernel (o filtro) e una regione locale dell'ingresso:
 |
(4.89) |
 rappresenta i pesi del filtro,
rappresenta i pesi del filtro,
 la porzione locale dell'immagine centrata in
la porzione locale dell'immagine centrata in  e
e  un eventuale bias.
un eventuale bias.
La convoluzione può essere applicata con stride diversi da 1, ottenendo cosı un layer di attivazione sottocampionato rispetto all'ingresso. Poiché i filtri riducono progressivamente le dimensioni delle mappe di attivazione, è frequente introdurre un padding per mantenere costante la dimensione in uscita.
Le mappe di attivazione (activation maps) vengono trasformate da una funzione di attivazione non lineare, tipicamente una ReLU. Successivamente, uno strato di pooling viene spesso inserito per ridurre la dimensionalità e introdurre invarianza locale: il max pooling è la scelta più comune, mentre l'average pooling o l'L2-norm pooling erano più diffusi in passato.
Le CNN sono progettate per trarre vantaggio da ingressi bidimensionali multicanale.
Una CNN prende in genere come ingresso un tensore di ordine 3 o 4; ad esempio, un'immagine  con 3 canali (R,G,B) rappresenta un tensore di ordine 3.
Ogni strato convolutivo può contenere
con 3 canali (R,G,B) rappresenta un tensore di ordine 3.
Ogni strato convolutivo può contenere  kernel differenti, generando in uscita mappe di attivazione di dimensione
kernel differenti, generando in uscita mappe di attivazione di dimensione
 .
.
L'architettura di una rete profonda (Deep Neural Network, DNN) può includere:
All'ultimo stadio (loss layer) viene applicato un metodo di classificazione tradizionale (MLP, AdaBoost o SVM) sulla rappresentazione ridotta dell'ingresso, conservando la maggior parte dell'informazione utile.
L'addestramento delle DNN avviene tipicamente tramite varianti della discesa stocastica del gradiente (vedi sezione 3.3.3), ottimizzando iterativamente i pesi dei filtri e degli strati completamente connessi sulla base dell'errore di classificazione.
Paolo medici