Next: M-Estimator Up: Regression and Optimization Methods Previous: Regression on a Conic
There exists a family of linear models that relate the dependent variable to the explanatory variables through a nonlinear function, known as generalized linear models. Logistic regression falls within this class of models, specifically in the case where the variable  is dichotomous, meaning it can only take on values
is dichotomous, meaning it can only take on values  or
or  . By its nature, this type of problem holds significant importance in classification tasks.
. By its nature, this type of problem holds significant importance in classification tasks.
In the case of binary problems, it is possible to define the probability of success and failure.
![\begin{displaymath}
\begin{array}{l}
P[Y=1\vert\mathbf{x}]=p(\mathbf{x}) \\
P[Y=0\vert\mathbf{x}]=1-p(\mathbf{x}) \\
\end{array}\end{displaymath}](img1022.svg) |
(3.96) |
The response of a linear predictor of the form
 |
(3.97) |
and , thus it is unsuitable for this purpose. It is necessary to associate the response of the linear predictor with the response of a certain function  , a probability function
, a probability function 
 |
(3.98) |
 , the mean function, is a nonlinear function defined over
, the mean function, is a nonlinear function defined over ![$[0,1]$](img189.svg) .
must be invertible, and the inverse
.
must be invertible, and the inverse  is the link function.
is the link function.
A widely used model for the function is the logit function defined as:
 , since it represents how many times success is greater than failure, is referred to as the odds-ratio. Consequently, the function (3.99) represents the logarithm of the probability of an event occurring relative to the probability of the same event not occurring (log-odds).
, since it represents how many times success is greater than failure, is referred to as the odds-ratio. Consequently, the function (3.99) represents the logarithm of the probability of an event occurring relative to the probability of the same event not occurring (log-odds).
Its inverse function exists and is given by
The maximum likelihood method in this case does not coincide with the least squares method but with
 |
(3.101) |
 |
(3.102) |
 .
.
Paolo medici
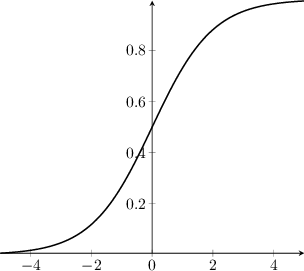

![\begin{displaymath}
\E[Y\vert\mathbf{x}] = p( \mathbf{x} ) = \frac{ e^{\boldsymb...
...dot \mathbf{x}} }{ 1 + e^{\boldsymbol\beta \cdot \mathbf{x}} }
\end{displaymath}](img1031.svg)