Next: Auto-Encoders Up: Deep Learning Previous: Representation learning
The breaking point between shallow and deep training techniques is considered to be 2006, when Hinton and others at the University of Toronto introduced Deep Belief Networks (DBNs) (HOT06), an algorithm that "greedily" trains a layered structure by training one layer at a time using an unsupervised training algorithm. The distinctive feature of DBNs lies in the fact that the layers are composed of Restricted Boltzmann Machines (RBMs) (FH94,Smo86).
Let
 be a binary stochastic variable associated with the visible state and
be a binary stochastic variable associated with the visible state and
 a binary stochastic variable associated with the hidden state. Given a state
a binary stochastic variable associated with the hidden state. Given a state
 , the energy of the configuration of the visible and hidden layers is given by (Hop82)
, the energy of the configuration of the visible and hidden layers is given by (Hop82)
 and
and  are the binary states of the visible layer and the hidden layer, respectively, while
are the binary states of the visible layer and the hidden layer, respectively, while  ,
,  are the weights, and
are the weights, and  are the weights associated between them. A Boltzmann Machine is similar to a Hopfield network, with the distinction that all outputs are stochastic. Therefore, a Boltzmann Machine can be defined as a special case of the Ising model, which in turn is a particular case of a Markov Random Field. Similarly, RBMs can be interpreted as stochastic neural networks where the nodes and connections correspond to neurons and synapses, respectively.
are the weights associated between them. A Boltzmann Machine is similar to a Hopfield network, with the distinction that all outputs are stochastic. Therefore, a Boltzmann Machine can be defined as a special case of the Ising model, which in turn is a particular case of a Markov Random Field. Similarly, RBMs can be interpreted as stochastic neural networks where the nodes and connections correspond to neurons and synapses, respectively.
The probability of the joint configuration
 is given by the Boltzmann distribution:
is given by the Boltzmann distribution:
 is defined as
is defined as
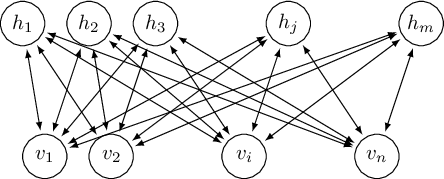
The term restricted refers to the fact that direct interactions between units belonging to the same layer are not permitted, but only interactions between adjacent layers are allowed.
Given an input  , the hidden binary state is activated with probability:
, the hidden binary state is activated with probability:
 |
(4.84) |
 is the logistic function
is the logistic function
 .
Similarly, it is straightforward to obtain the visible state from the hidden state:
.
Similarly, it is straightforward to obtain the visible state from the hidden state:
 |
(4.85) |
Obtaining the model
that allows for the representation of all training input values is, however, a very complex task. A much faster procedure was proposed by Hinton in 2002: it is only since then that RBMs can be trained using the contrastive divergence (CD) algorithm (Hin12).
Paolo medici