Next: Gaussiana campionata Up: Elementi di Statistica Previous: Media e Varianza
La distribuzione Gaussiana è una delle distribuzioni di probabilità più diffuse nei problemi pratici in quanto modella buona parte della distribuzione di probabilità in eventi reali. In questo documento in particolare è usata nei filtri (sezione 2.12) e nei classificatori Bayesiani (sezione 4.2), in LDA (sezione 4.3).
 , è quella di densità
, è quella di densità
 |
(2.14) |
 , con
, con
 , è quella che si ottiene dalla distribuzione standard con la trasformazione
, è quella che si ottiene dalla distribuzione standard con la trasformazione
 .
.
Nel caso univariabile (gaussiana univariata) la gaussiana ha la seguente funzione di distribuzione:
 è il valor medio e
è il valor medio e  è la varianza.
All'interno di
è la varianza.
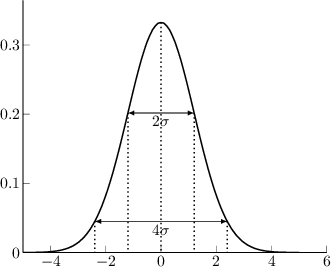
All'interno di  da si concentra il 68% della probabilità, in
da si concentra il 68% della probabilità, in  il 95% e in
il 95% e in  il 99.7%.
il 99.7%.
La distribuzione gaussiana multivariabile (gaussiana multidimensionale) è data da un vettore
 di dimensione
di dimensione  , rappresentante il valor medio delle varie componenti, e da una matrice di covarianza
, rappresentante il valor medio delle varie componenti, e da una matrice di covarianza
 di dimensioni
di dimensioni  :
:
![$\boldsymbol\mu = \left[ \mu_1, \mu_2, \dots \mu_n \right]^{T}$](img452.svg) e covarianza
e covarianza
 .
.
Si può anticipare che la quantità a esponente dell'equazione (2.16) è la distanza di Mahalanobis (sezione 2.4) tra  e
.
e
.
Quando le variabili aleatorie sono tra loro indipendenti e di varianza uguale, la matrice
è una matrice diagonale con valori tutti uguali a  e la distribuzione di probabilità normale multivariata si riduce a
e la distribuzione di probabilità normale multivariata si riduce a