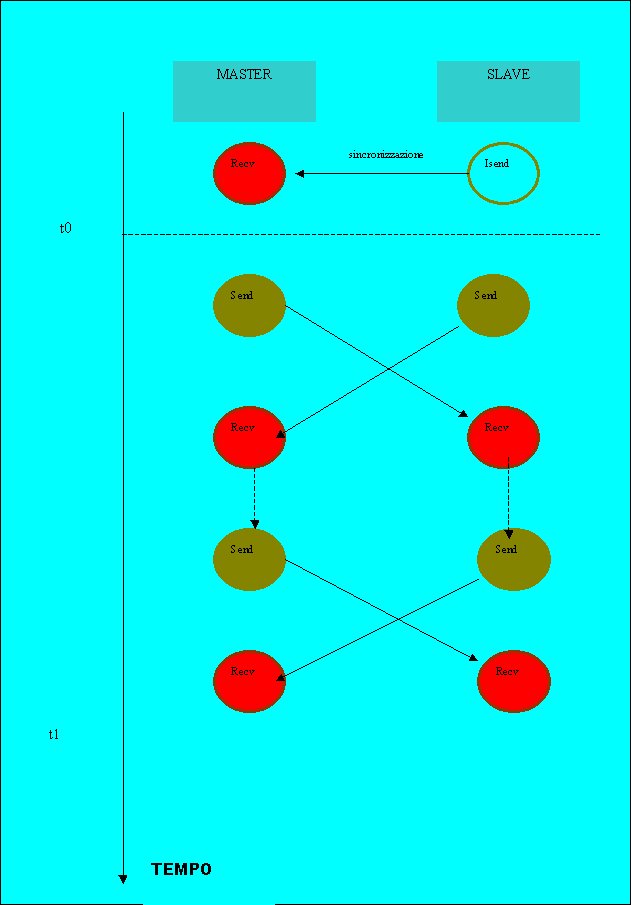
Il nucleo della funzione che implementa il test Head to Head è :
elapsed_time = 0;
if(ctx->is_master){ /*sono il processo master? cioè il mio pid è 0?*/
recv_from = MPI_ANY_SOURCE;
if (source_type==SpecifiedSource) recv_from = to;/*to è lo
slave, il proc con pid size-1*/
MPI_Recv(rbuffer,len,MPI_BYTE,recv_from,0,MPI_COMM_WORLD,&status);
/*sincronizzazione*/
t0=MPI_Wtime();
for(i=0;i<reps;i++){
MPI_Send(sbuffer,len,MPI_BYTE,to,MSG_TAG(i),MPI_COMM_WORLD);
MPI_Recv(rbuffer,len,MPI_BYTE,recv_from,MSG_TAG(i),MPI_COMM_WORLD,&status);
}
t1 = MPI_Wtime();
elapsed_time = t1-t0;
}
if(ctx->is_slave){/*sono lo slave?cioè il compagno di master?cioè il proc
con pid size-1?*/
recv_from = MPI_ANY_SOURCE;
if (source_type == SpecifiedSource) recv_from = to;/to è il
master*/
MPI_Send(sbuffer,len,MPI_BYTE,from,0,MPI_COMM_WORLD);/*sincronizzazione*/
for(i=0;i<reps;i++){
MPI_Send(sbuffer,len,MPI_BYTE,to,MSG_TAG(i),MPI_COMM_WORLD);
MPI_Recv(rbuffer,len,MPI_BYTE,recv_from,MSG_TAG(i),MPI_COMM_WORLD,&status);
}
}
dove :
Come si vede c'è molto più parallelismo di esecuzione rispetto alla Roundtrip. Infatti i Risultati mostreranno come la trasmissione con questo test sia molto più veloce in entrambi i sistemi MPICH e MPICH-G2. La cosa interessante è però che, con questo test, MPICH-G2 risulta più veloce anche rispetto a MPICH se la dimensione dei pacchetti abbastanza è grande.Nella sezione Conclusioni cercheremo di dare una spiegazione a questo fenomeno.
L'algoritmo :
L'ultima fase è quella si smoothing dove una apposita funzione scorre la lista dei risultati e per ogni nodo calcola una stima del suo valore in base al precedente ed al successivo :
t_est:= (t_successivo-t_precedente)/(dim_msg_successivo-dim_msg_precedente)*(dim_msg_attuale-dim_msg_precedente) + t_precedente.
se il risultato del test è sbagliato di oltre il 10% rispetto al tempo stimato si ripete il test di quel particolare nodo.