Conclusioni
Lo scopo principale di questa tesina era quello di misurare le prestazioni di
comunicazione di MPICH-G2 e confrontarle, dove possibile, con quelle di MPICH.
Questo per capire quanto le complesse operazioni di gestione dell'ambiente Grid,
svolte tramite i servizi GlobusToolkit, producessero overhead nella spedizione e
ricezione di messaggi.
In base ai Risultati ottenuti nei test
analizziamo il comportamento di MPICH-G2 i ambiente LAN e WAN.
In questa sezione vengono esposti solo test in versione bloccante (vedi
Bloccanti e non bloccanti), in quanto non abbiamo
rilevato nessuna differenza con le versioni non bloccanti.. Nella sezione
Risultati sono comunque consultabili i test di
entrambe le versioni.
Test su LAN
A questi test è necessaria una piccola premessa. Come abbiamo anticipato
nella sezione Communication Management, la
documentazione ufficiale di MPICH-G2 (MPICH-G2: A Grid-Enabled
Implementation of the Message Passing Interface, N. Karonis, B. Toonen, and
I. Foster) riporta come attualmente MPICH-G2 non sia stato ancora ottimizzato
completamente per il funzionamento TCP/IP. Questo rende un pò difficile
capire dove le prestazioni siano peggiori per l'intervento di GlobusToolkit o
per la mancanza di ottimizzazioni rispetto a MPICH. Proveremo comunque a trarre
alcune conclusioni.
Abbiamo misurato la latenza con i test Roundtrip
e Head to Head utilizzando messaggi da 0 a 50 byte con
incrementi di 1 (block_R5,block_H5)
ottenendo i seguenti risultati :
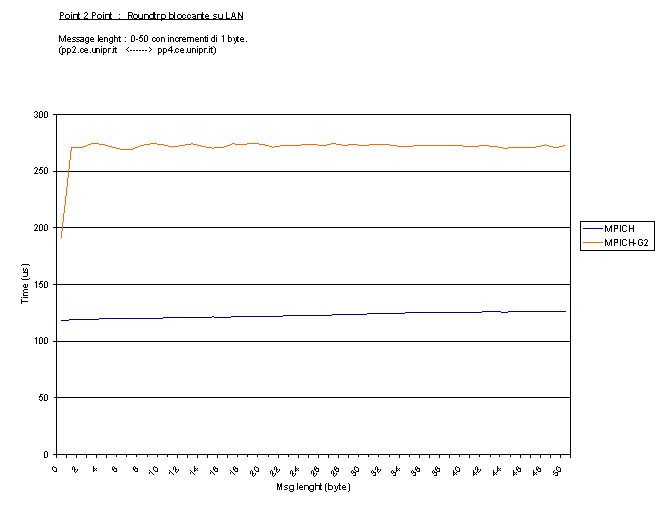
Come si può notare esiste MPICH-G2 soffre di un overhead di circa il
55% per messaggi con dimensione 0, mentre si arriva ad oltre il 100% con
messaggi > 0 byte. Questo dovrebbe essere dovuto certamente a ritardi legati a
GlobudToolkit, ma anche al fatto che attualmente MPICH-G2 usa due chiamate di
sistema separate per lo header del messaggio e per i dati effettivi. Quindi
quando il messaggio è zero viene spedito solo lo header producendo prestazioni
migliori. Da ciò si può dedurre che unendo header e dati i pacchetti in un solo
vettore si potrebbero ottenere prestazioni migliori.
La differenza tra Roundtrip e Head to Head è dovuto solamente al diverso
algoritmo che utilizzano, dove Head to Head è più parallelo, Ma percentualmente
le differenze sono le stesse.
Con gli stessi test della latenza, ma con messaggi più grandi (block_R100,
block_H100), si può osservare quanta
banda riescono ad occupare MPICH e MPICH-G2 :
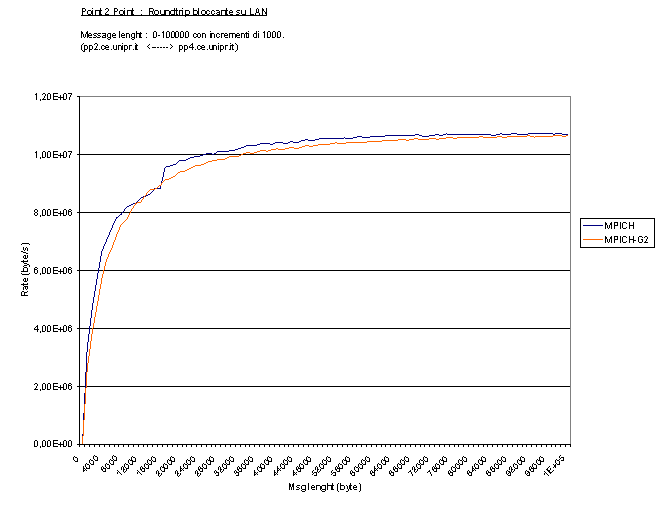
è interessante notare come, con messaggi abbastanza grandi, le prestazioni di
MPICH ed MPICH-G2 siano praticamente identiche. Entrambi, con un byte rate
massimo di circa 86Mbs, si avvicinano molto alla totale occupazione della banda
disponibile di 100Mbs. Inoltre, osservando il test
block_R16 riportato sotto, è possibile
dedurre che questo avvicinamento non è dovuto semplicemente al fatto che l'overhead
presente per piccoli messaggi diventi trascurabile con quelli grandi, ma il
divario diminuisce chiaramente al crescere della dimensione dei messaggi. Questo
potrebbe essere dovuto alla diversa implementazione di MPICH-G2 delle primitive
di spedizione MPI_xsend. Come già anticipato (Communication
Management) MPICH-G2 utilizza direttamente il buffer utente per eseguire una
spedizione, senza crearne uno appositamente per la funzione send. Questo
per messaggi grandi avvantaggia MPICH-G2, che recupera il divario iniziale
creato dalla gestione separata di dati e header e dalle operazioni di
GlobusToolkit.
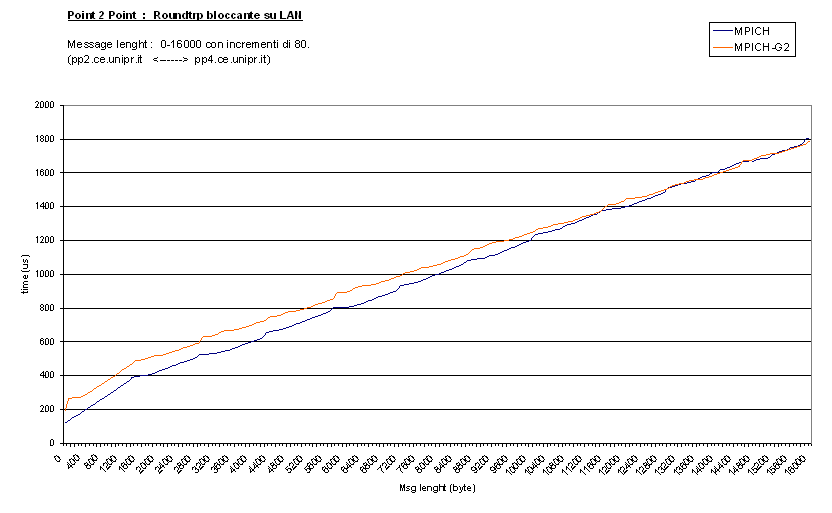
Vediamo ora cosa succede in particolare con il test Head to Head
a regime :
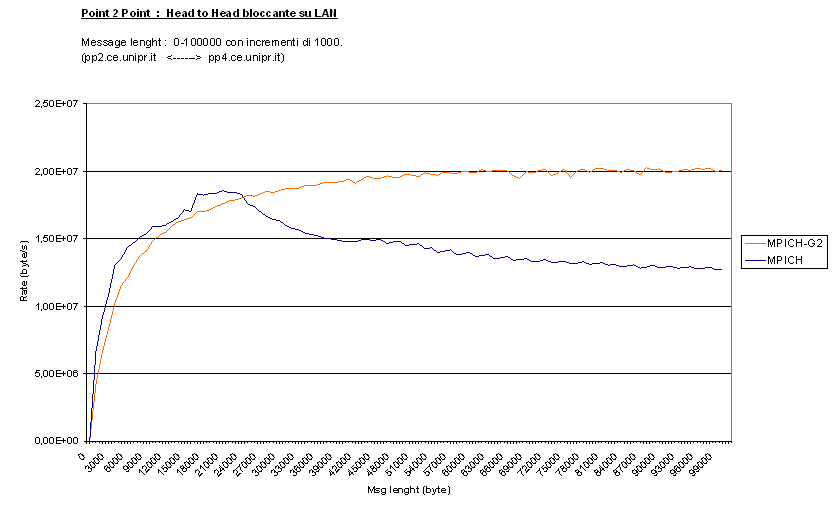
Qui MPICH-G2 riesce ancora ad occupare circa la stessa banda che
prendeva con Roundtrip, ma, essendo la spedizione effettuata in parallelo dai
due processi coinvolti, il byte rate raddoppia, raggiungendo i 160Mbis
bi-direzionali su 200Mbs disponibili. MPICH invece raggiunge un massimo di
18Mbyte/s intorno ai 20000byte di pacchetto.
Per primo commentiamo il test BroadcastRound
effettuato con quattro messaggi di dimensione diversa (bcast_short,bcast_long)
:
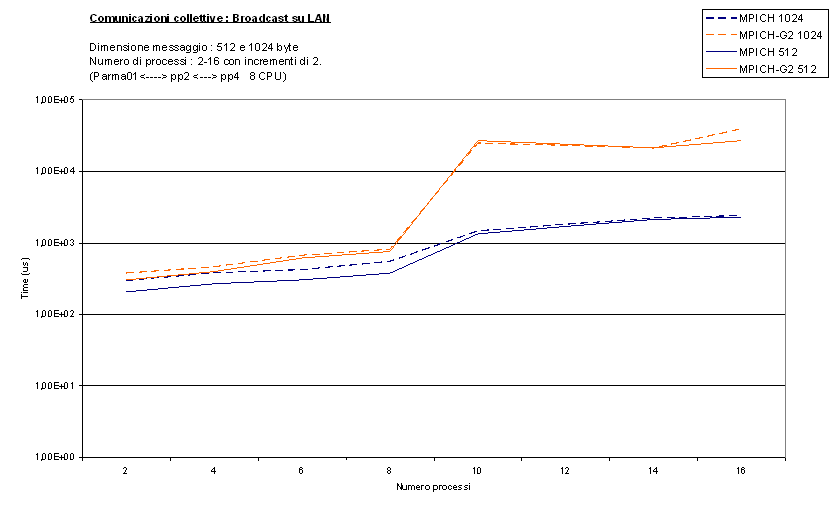
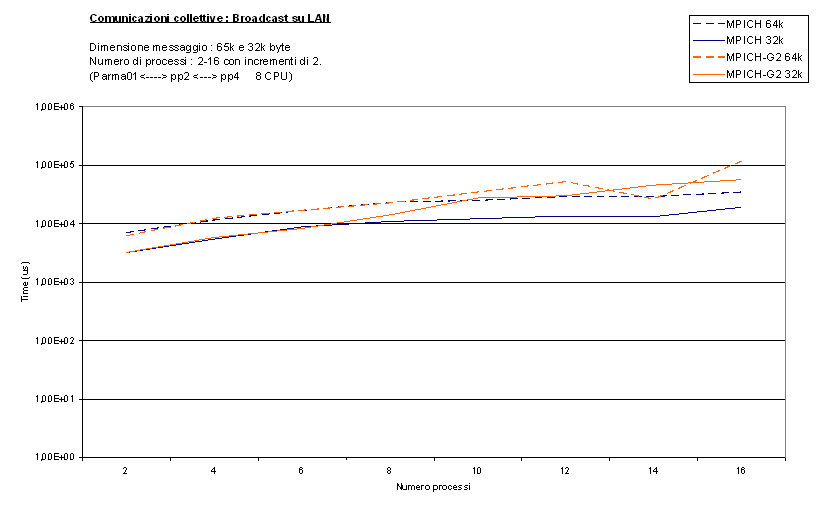
come si può notare MPICH-G2 soffre particolarmente il passaggio da 8 a 10
processi, cioè quando iniziano ad esserci più processi su di una stessa CPU. La
ragione di questo problema, secondo noi, va cercata nella maggiore occupazione
di CPU da parte dei processi MPICH-G2. Anche osservando il tempo di CPU
richiesto durante l'esecuzione, utilizzando un semplice top, si nota come
MPICH-G2 richieda sempre percentuali molto elevate del tempo di CPU (in genere
oltre il 90%), anche rispetto a MPICH (che si ferma a 30%). Quindi, nel momento
in cui una singola CPU viene divisa tra due o più processi, è naturale
aspettarsi un peggioramento delle prestazioni così marcato. Come sempre per
messaggi grandi le differenze si affievoliscono, confermando la presenza di
ottimizzazioni parziali in MPICH-G2, concentrate principalmente su messaggi di
grande dimensione.
Vediamo cosa succede invece con una variante di
Broadcast, anche qui con messaggi di diversa dimensione (bcastal_short,
bcastalt_long) :
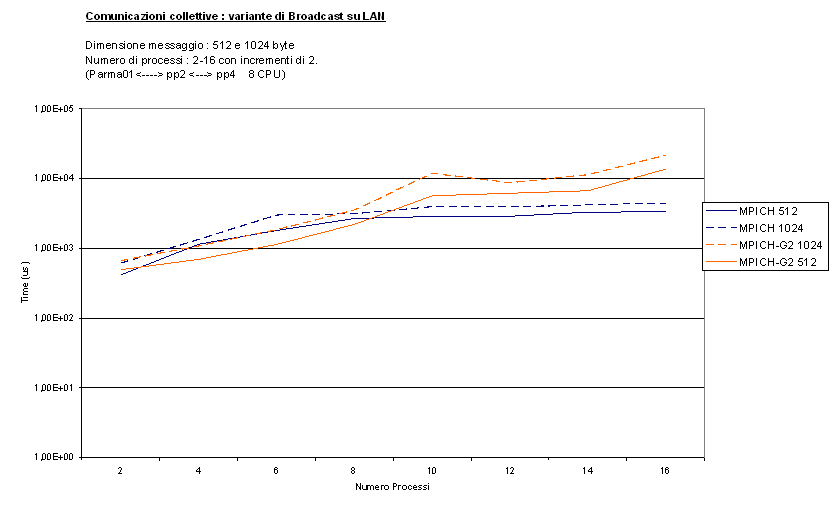
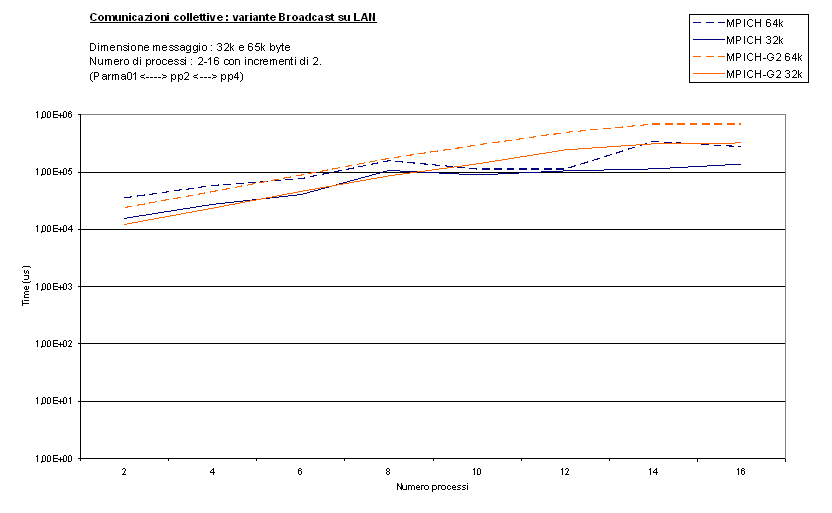
ora le differenze sono molto minori, sia per messaggi grandi che piccoli.
Probabilmente ciò è dovuto al diverso algoritmo utilizzato da questo test, che
riesce ad evitare che più di una MPI_Broadcast venga eseguita
contemporaneamente, diminuendo il carico di lavoro per ogni CPU. Quindi in
questo caso MPICH-G2 sente di meno la presenza di più processi su una singola
CPU. Inoltre questo test ci permette di concludere che l'implementazione della
MPI_Broadcast su LAN è la stessa sia per MPICH che per MPICH-G2, potendo quindi
imputare, con maggiore sicurezza, la differenza di prestazioni nel test
precedente alle diverse occupazioni di CPU.
Nella sezione Risultati sono disponibili altri
due tipi di test, Reduction con Double e Sincronizzazione, per i
quali valgono considerazioni analoghe a quelle per BroadcastRound.
Test su WAN
E' necessario premettere che i test su WAN sono sempre stati molto
influenzati dalle particolari condizioni di traffico nel momento in cui venivano
eseguiti, dando spesso risultati abbastanza diversi tra loro. I test più
importanti (quelli riportati qui) sono stati tutti ripetuti 3 volte, e abbiamo
deciso di commentare i risultati migliori ottenuti, considerando gli altri
frutto di traffico eccessivo su rete.
La latenza in ambiente WAN è stata misurata con i soliti test
Roundtrip e Head to Head
utilizzando messaggi da 0 a 50 byte con incrementi di 1 (c_block_H5_3,
c_block_R5_3):
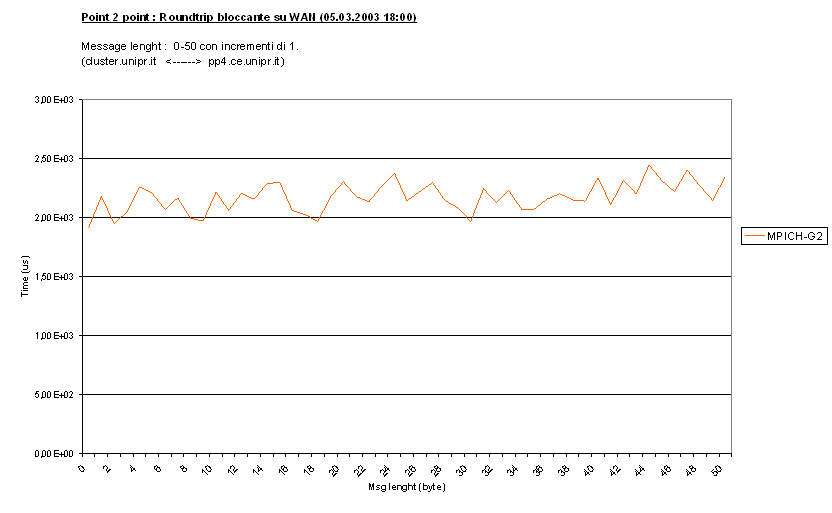
come si può vedere l'andamento di questi grafici è il medesimo che
su LAN, ma i tempi sono di altro ordine di grandezza. Su WAN è presente una
latenza dell'ordine dei milli secondi, di ben tre ordini di grandezza superiore
a quella su LAN. Anche qui abbiamo diversi valori tra messaggi di dimensione 0 e
quelli superiori, sempre per il problema dei pacchetti separati per dati e
header.
Con gli stessi test ma con messaggi più grandi (c_block_H30
, c_block_R30)è possibile osservare il
byte rate massimo raggiunto da MPICH-G2 su WAN :
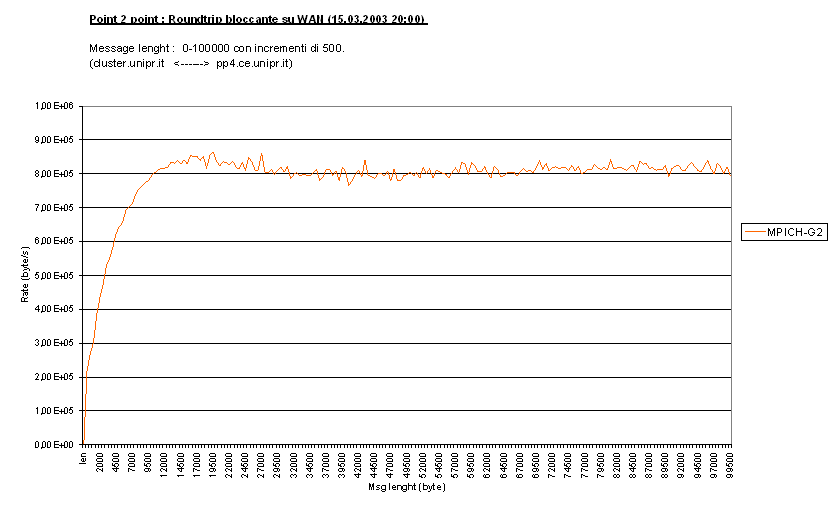
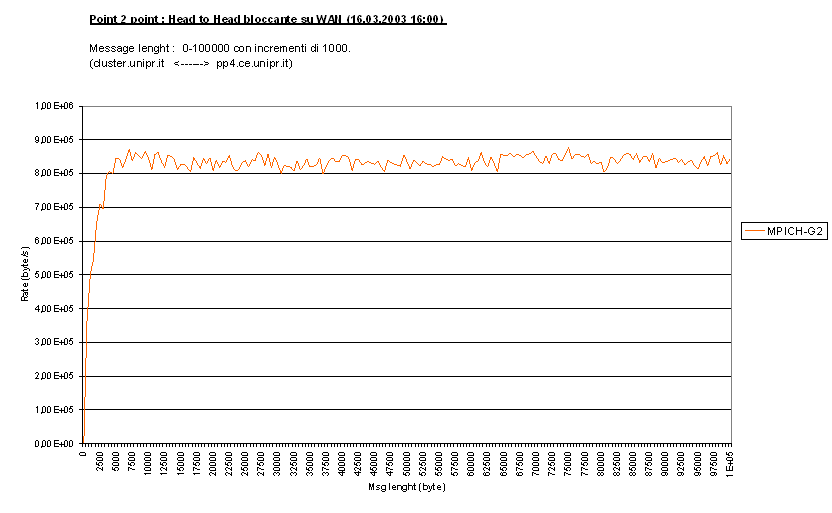
qui non si riesce ad occupare più di 6.4Mbs dei 10Mbs
disponibili, percentuale comunque piuttosto alta, tenuto conto che la rete
utilizzate che collega al Centro di Calcolo al cluster Parma2 è utilizzata da
molti utenti a tutte le ore del giorno e della notte. Notare come la banda viene
saturata molto presto, già con messaggi di 10000 byte (per Roundtrip) si è
raggiunto il massimo, e che la limitata banda appiattisca le differenze tra
Roundtrip e Head to Head
Vediamo i due test principali (bcast_wan,
bcastalt_wan) eseguiti con
messaggi di 512 e 64k byte su 4 CPU divise tra il Centro di Calcolo e il Cluster
Parma2 :
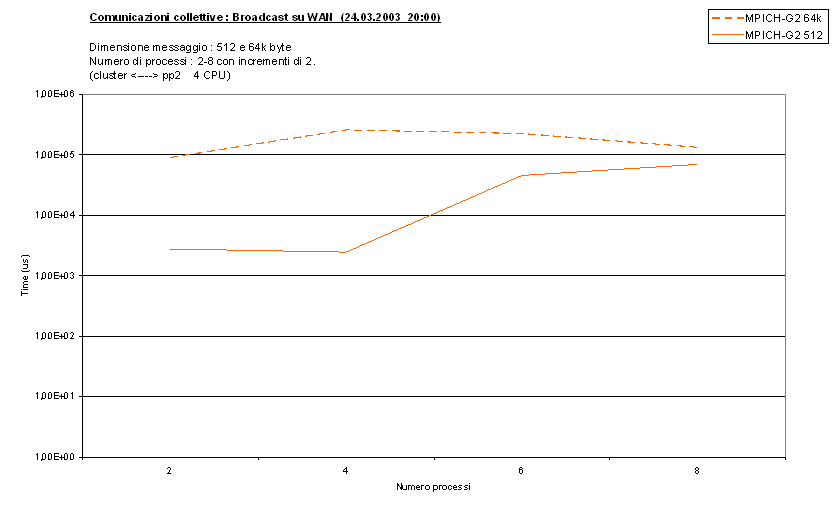
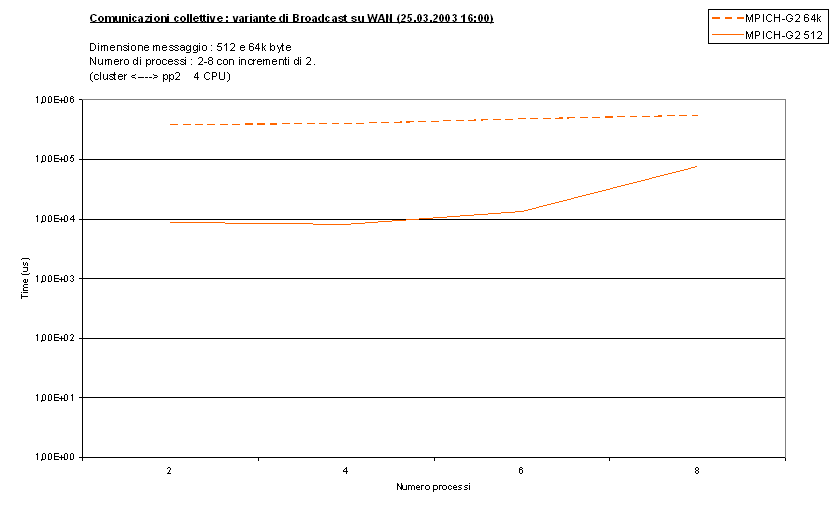
Come vediamo i risultati sono analoghi a quelli su LAN. Anche in
questo caso il passaggio a più processi è particolarmente penalizzante nella
Broadcast classica a causa dell'altra richiesta di CPU da parte di MPICH-G2. Un
pò meno nella variante di Broadcast in quanto richiede meno tempo di CPU.
Si può comunque notare che i tempi sono cresciuti di almeno un
ordine di grandezza rispetto alla LAN, in linea con tutti gli altri test.
Riassunto Punto Punto
| |
Latenza LAN |
Byte Rate LAN |
Latenza WAN |
Byte Rate WAN |
| MPICH |
118,27 us |
10,7 Mbyte/s |
- |
- |
| MPICH-G2 |
270,5 us(*) 191,14 us(**) |
10,6 Mbyte/s |
2*10e3 us circa |
800Kbyte/s circa |
(*) dimensione messaggio >0
(**) dimensione messaggio = 0
Riassunto Collettive (4 CPU, un processo per ogni CPU)
| |
BCAST LAN 512 byte |
BCAST LAN 64k byte |
BCAST WAN 512 byte |
BCAST WAN 64k byte |
| MPICH |
270,32 us |
11481,06 us |
- |
- |
| MPICH-G2 |
400,05 us |
12350,16 us |
2471,11 us |
257164,62 us |