Next: ADAptive BOOSTing Up: Ensemble Learning Previous: Ensemble Learning
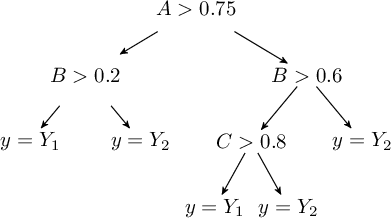
A Decision Tree is a very simple and effective method for creating a classifier, and the training of decision trees is one of the most successful current techniques. A decision tree is a tree of classifiers (Decision Stump) where each internal node is associated with a specific "question" regarding a feature. From this node, as many branches emanate as there are possible values that the feature can take, leading to the leaves that indicate the category associated with the decision. Special attention is typically given to binary decision nodes.
A good "question" divides samples of heterogeneous classes into subsets with fairly homogeneous labels, stratifying the data in such a way as to minimize variance within each stratum.
To enable this, it is necessary to define a metric that measures this impurity. We define  as a subset of samples from a particular training set consisting of
as a subset of samples from a particular training set consisting of  possible classes. is, in fact, a random variable that takes only discrete values (the continuous case is analogous). It is possible to associate with each discrete value
possible classes. is, in fact, a random variable that takes only discrete values (the continuous case is analogous). It is possible to associate with each discrete value  , which can take , the probability distribution
, which can take , the probability distribution  . is a data set composed of classes, and
. is a data set composed of classes, and  is the relative frequency of class
is the relative frequency of class  within the set .
within the set .
 |
Given the definition of , the following metrics are widely used in decision trees:
 of is given by:
of is given by:
 |
(4.46) |
 |
(4.47) |
 |
(4.48) |
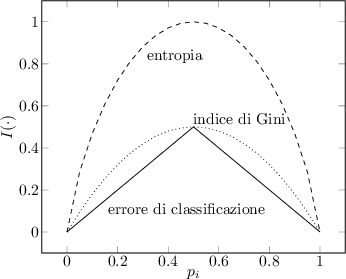
Intuitively, a node with class distribution  has minimal impurity, while a node with uniform distribution
has minimal impurity, while a node with uniform distribution  has maximal impurity.
has maximal impurity.
A "question"  , which has
, which has  possible answers, divides the set
possible answers, divides the set  into the subsets
into the subsets
 .
.
To evaluate how well the condition is executed, one must compare the impurity level of the child nodes with the impurity of the parent node: the greater their difference, the better the chosen condition.
Given a metric  that measures impurity, the gain
that measures impurity, the gain  is a criterion that can be used to determine the quality of the split:
is a criterion that can be used to determine the quality of the split:
 |
(4.49) |
 is the number of samples in the parent node and
is the number of samples in the parent node and
 is the number of samples in the i-th child node.
is the number of samples in the i-th child node.
If entropy is used as a metric, the gain is known as Information Gain (TSK06).
Decision trees induce algorithms that select a test condition that maximizes the gain . Since
 is the same for all possible classifiers and
is constant, maximizing the gain is equivalent to minimizing the weighted sum of the impurities of the child nodes:
is the same for all possible classifiers and
is constant, maximizing the gain is equivalent to minimizing the weighted sum of the impurities of the child nodes:
 |
(4.50) |
is the one that minimizes this quantity.
In the case of binary classifiers, the Gini metric is widely used, as the gain to be minimized reduces to
 |
(4.51) |
 being the number of positive and negative samples that the classifier moves to the left branch and
being the number of positive and negative samples that the classifier moves to the left branch and  being the number of samples in the right branch.
being the number of samples in the right branch.
Decision trees adapt both very well and quickly to training data and consequently, if not constrained, they systematically suffer from the problem of overfitting. Typically, a pruning algorithm is applied to trees to reduce, where possible, the issue of overfitting.
Pruning approaches are generally of two types: pre-pruning and post-pruning. Pre-pruning involves stopping the creation of the tree under certain conditions to avoid excessive specialization (for example, maximum tree size). In contrast, post-pruning refines an already created tree by removing branches that do not meet specific conditions on a previously selected validation set.
This technique for creating a decision tree is commonly referred to as Classification and Regression Trees (CART) (B$^+$84). Indeed, in real cases where the analyzed features are statistical quantities, we do not refer to creating a classification tree, but more appropriately to constructing a regression tree. Finding the optimal partition of the data is an NP-complete problem; therefore, greedy algorithms, such as the one presented in the section, are typically employed.
Paolo medici